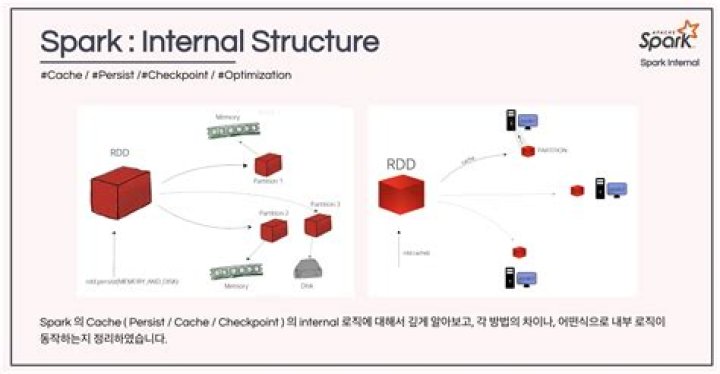
Caching or persistence are optimisationtechniques for (iterative and interactive) Sparkcomputations. They help saving interim partial results so they canbe reused in subsequent stages. These interim results as RDDs arethus kept in memory (default) or more solid storages like diskand/or replicated..
In respect to this, how do I clear my spark cache?
cache() just calls persist() , so toremove the cache for an RDD, call unpersist() .sc.getPersistentRDDs is a Map which stores the details of thecached data. This is weird.
Additionally, which storage level does the cache () function use? Level of storage for rdd cachefunction is memory_only. In this storage level, RDD isstored as deserialized Java object in the JVM. If the sizeof RDD is greater than memory, It will not cache somepartition and recompute them next time wheneverneeded.
Subsequently, question is, what is caching and how is it used?
Memory Cache This caching mechanism is used incomputers to help speed up the delivery of data within anapplication. The memory cache stores certain parts of datain Static RAM (SRAM) as it is faster to access files using thismethod rather than accessing them via the harddrive.
How can I improve my spark performance?
Optimize Apache Spark jobs in HDInsight
- Choose the data abstraction.
- Use optimal data format.
- Select default storage.
- Use the cache.
- Use memory efficiently.
- Optimize data serialization.
- Use bucketing.
- Optimize joins and shuffles.
Related Question Answers
When should you use spark cache?
Caching or persistence are optimisationtechniques for (iterative and interactive) Sparkcomputations. They help saving interim partial results so they canbe reused in subsequent stages. These interim results as RDDs arethus kept in memory (default) or more solid storages like diskand/or replicated.What is difference between cache and persist in spark?
The difference among them is that cache()will cache the RDD into memory, whereaspersist(level) can cache in memory, on disk, oroff-heap memory according to the caching strategy specifiedby level. persist() without an argument is equivalent withcache().What is Dag spark?
(Directed Acyclic Graph) DAG in ApacheSpark is a set of Vertices and Edges, where verticesrepresent the RDDs and the edges represent the Operation to beapplied on RDD. In Spark DAG, every edge directs fromearlier to later in the sequence.What is spark RDD?
Resilient Distributed Datasets (RDD) is afundamental data structure of Spark. It is an immutabledistributed collection of objects. Each dataset in RDD isdivided into logical partitions, which may be computed on differentnodes of the cluster.Which are the methods to create RDD in spark?
There are three ways to create an RDD in Spark. - Parallelizing already existing collection in driverprogram.
- Referencing a dataset in an external storage system (e.g. HDFS,Hbase, shared file system).
- Creating RDD from already existing RDDs.
What is parallelize in spark?
When spark parallelize method is applied on aCollection (with elements), a new distributed data set is createdwith specified number of partitions and the elements of thecollection are copied to the distributed dataset (RDD). Meaningparallelize() method is not actually acted upon until thereis an action on the RDD.What is meant by RDD lazy evaluation?
The name itself indicates its definition, LazyEvaluation means that the execution will not start until anaction is triggered. In Spark, lazy evaluation comes whenSpark transformation occurs. Transformations are lazy innature meaning when we call some operation in RDD, itdoes not execute immediately.What is an action in spark?
Actions. Actions are RDD operations thatproduce non-RDD values. They materialize a value in a Sparkprogram. In other words, a RDD operation that returns a value ofany type but RDD[T] is an action.Why should I clear cache?
Clear out all cached app data The “cached” data used by yourcombined Android apps can easily take up more than agigabyte of storage space. These caches of data areessentially just junk files, and they can be safely deleted to freeup storage space. Tap the Clear Cache button to take out thetrash.What is the purpose of cache?
The purpose of cache memory is to store programinstructions and data that are used repeatedly in the operation ofprograms or information that the CPU is likely to need next. Thecomputer processor can access this information quickly from thecache rather than having to get it from computer's mainmemory.How is cache stored?
In modern computers, the cache memory isstored between the processor and DRAM; this is called Level2 cache. On the other hand, Level 1 cache is internalmemory caches which are stored directly on theprocessor.Why is cache used?
Like memory caching, disk caching is usedto access commonly accessed data. However, instead of usinghigh-speed SRAM, a disk cache uses conventional main memory.The most recently accessed data from a disk is stored in a memorybuffer.What is the difference between cache and RAM?
The difference between cache and RAM is that thecache is a fast memory component that stores thefrequently used data by the CPU while RAM is a computingdevice that stores data and programs currently used by the CPU. Inbrief, the cache is faster and expensive thanRAM.Why do we use cache?
The data in a cache is generally stored in fastaccess hardware such as RAM (Random-access memory) and may also beused in correlation with a software component. Acache's primary purpose is to increase data retrievalperformance by reducing the need to access the underlying slowerstorage layer.What is cache on a computer?
The cache (pronounced "cash") is a space in yourcomputer's hard drive and in RAM memory where your browsersaves copies of previously visited Web pages. Your browser uses thecache like a short-term memory.What is cache and its types?
Generally, some instructions and data which is requiredby the CPU are stored in this cache memory. Now let's knowthe different types of the cache memory. There arethree types of cache Memory, Level 1 CacheMemory. Level 2 Cache Memory.Is cached data important?
The main reason why cached data exists is to makeloading time faster. All apps, whether they are system apps orthird party apps will have cached data. Since cacheddata is automatically created and it does not include anyimportant data, wiping or clearing the cache for anapp or a device is harmless.Why is RDD immutable?
Resilient because RDDs are immutable(can'tbe modified once created) and fault tolerant, Distributed becauseit is distributed across cluster and Dataset because it holds data.So why RDD? Apache Spark lets you treat your input filesalmost like any other variable, which you cannot do in HadoopMapReduce.Where is RDD stored?
In this storage level, RDD is stored onlyon disk. The space used for storage is low, the CPU computationtime is high and it makes use of on disk storage.