What is Skip gram architecture?
What is Skip gram architecture?
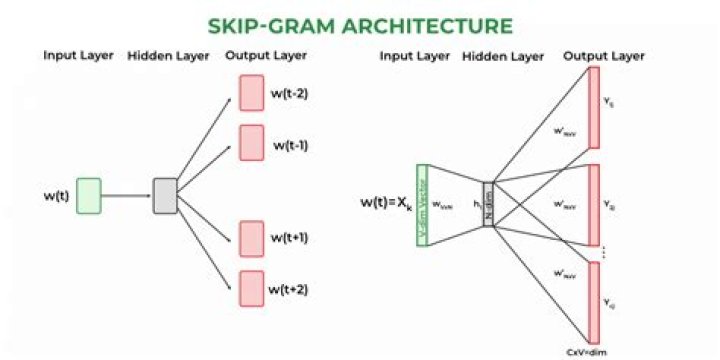
The Skip-gram model architecture usually tries to achieve the reverse of what the CBOW model does. It tries to predict the source context words (surrounding words) given a target word (the center word). Thus the model tries to predict the context_window words based on the target_word. …
What is the skip gram approach?
Skip-gram is one of the unsupervised learning techniques used to find the most related words for a given word. Skip-gram is used to predict the context word for a given target word. Here, target word is input while context words are output.
What is Word2Vec skip gram?
Skip-gram Word2Vec is an architecture for computing word embeddings. Instead of using surrounding words to predict the center word, as with CBow Word2Vec, Skip-gram Word2Vec uses the central word to predict the surrounding words.
Is Skip gram better than CBOW?
According to the original paper, Mikolov et al., it is found that Skip-Gram works well with small datasets, and can better represent less frequent words. However, CBOW is found to train faster than Skip-Gram, and can better represent more frequent words.
How is GloVe trained?
The GloVe model is trained on the non-zero entries of a global word-word co-occurrence matrix, which tabulates how frequently words co-occur with one another in a given corpus. For example, consider the co-occurrence probabilities for target words ice and steam with various probe words from the vocabulary.
What is Doc2Vec model?
Doc2Vec model, as opposite to Word2Vec model, is used to create a vectorised representation of a group of words taken collectively as a single unit. It doesn’t only give the simple average of the words in the sentence.
What is Gram Gram and Skip?
N-gram is a basic concept of a (sub)sequnece of consecutive words taken out of a given sequence (e.g. sentence). k-skip-n-gram is a generalization where ‘consecutive’ is dropped. It is ‘just’ subsequence of the original sequence, e.g. every other word of the sentence is 2-skip-n-gram.
What is Skip-gram and CBOW models?
In the CBOW model, the distributed representations of context (or surrounding words) are combined to predict the word in the middle. While in the Skip-gram model, the distributed representation of the input word is used to predict the context.
What is the main difference between Skip-gram and CBOW?
CBOW is trained to predict a single word from a fixed window size of context words, whereas Skip-gram does the opposite, and tries to predict several context words from a single input word.
Why CBOW is faster than skip-gram?
The skip-gram approach involves more calculations. Specifically, consider a single ‘target word’ with a context-window of 4 words on either side. In CBOW, the vectors for all 8 nearby words are averaged together, then used as the input for the algorithm’s prediction neural-network.
Is GloVe unsupervised?
GloVe, coined from Global Vectors, is a model for distributed word representation. The model is an unsupervised learning algorithm for obtaining vector representations for words.
What is NLP GloVe?
Introduction. GloVe is an unsupervised learning algorithm for obtaining vector representations for words. Training is performed on aggregated global word-word co-occurrence statistics from a corpus, and the resulting representations showcase interesting linear substructures of the word vector space.