Is spark an ETL?
.
Accordingly, is Databricks an ETL tool?
Databricks was founded by the creators of Apache Spark and offers a unified platform designed to improve productivity for data engineers, data scientists and business analysts. Azure Databricks, is a fully managed service which provides powerful ETL, analytics, and machine learning capabilities.
Subsequently, question is, can Python be used for ETL? Luckily, there are plenty of ETL tools on the market. From JavaScript and Java to Hadoop and GO, you can find a variety of ETL solutions that fit your needs. But, it's Python that continues to dominate the ETL space. There are well over a hundred Python tools that act as frameworks, libraries, or software for ETL.
Then, is spark a data warehouse?
Spark is a platform that simplifies data movement in clustered environments. In order to understand how it can be used, it's helpful to compare it to a traditional data warehousing environment.
Will Hadoop replace ETL?
No not at all, Hadoop is not a replacement for ETL because hadoop is actually a high performance distributed computing program. Hadoop has not replaced nor it will replace ETL in the coming time because Hadoop complements ETL for the processing of Bigdata.
Related Question AnswersIs Databricks a database?
A Databricks database is a collection of tables. A Databricks table is a collection of structured data. This means that you can cache, filter, and perform any operations supported by DataFrames on tables. You can query tables with Spark APIs and Spark SQL.What is Databricks used for?
Databricks is an industry-leading, cloud-based data engineering tool used for processing and transforming massive quantities of data and exploring the data through machine learning models. Recently added to Azure, it's the latest big data tool for the Microsoft cloud.What is ETL in spark?
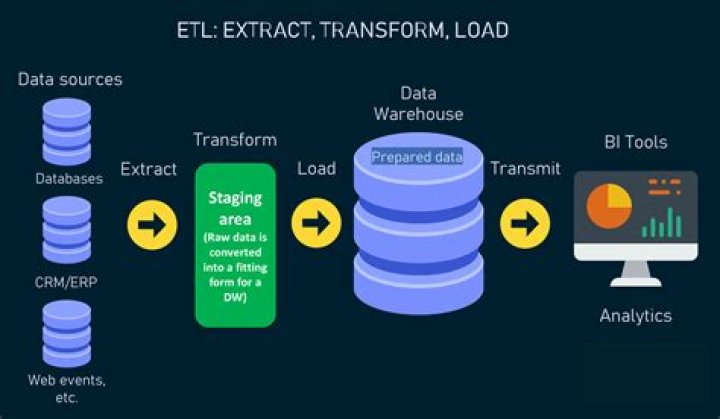
ETL stands for EXTRACT, TRANSFORM and LOAD 2. Goal is to clean or curate the data - Retrieve data from sources (EXTRACT) - Transform data into a consumable format (TRANSFORM) - Transmit data to downstream consumers (LOAD) 8 An ETL Query in Apache Spark spark.read.json("/source/path") .filter() .What is Databricks platform?
Azure Databricks is an Apache Spark-based analytics platform optimized for the Microsoft Azure cloud services platform. Azure Databricks is a fast, easy, and collaborative Apache Spark-based analytics service.What is Databricks Delta?
Databricks Delta, a component of the Databricks Unified Analytics Platform, is an analytics engine that provides a powerful transactional storage layer built on top of Apache Spark. It helps users build robust production data pipelines at scale and provides a consistent view of the data to end users.What are ETL pipelines?
An ETL Pipeline refers to a set of processes extracting data from an input source, transforming the data, and loading into an output destination such as a database, data mart, or a data warehouse for reporting, analysis, and data synchronization. The letters stand for Extract, Transform, and Load.What does ETL stand for?
extract, transform, loadWhat is Databricks Azure?
Azure Databricks is an Apache Spark-based analytics platform optimized for the Microsoft Azure cloud services platform. For a big data pipeline, the data (raw or structured) is ingested into Azure through Azure Data Factory in batches, or streamed near real-time using Kafka, Event Hub, or IoT Hub.Are ETL tools dead?
ETL is not dead. In fact, it has become more complex and necessary in a world of disparate data sources, complex data mergers and a diversity of data driven applications and use cases.What is ETL Python?
Using Python for ETL: tools, methods, and alternatives. Extract, transform, load (ETL) is the main process through which enterprises gather information from data sources and replicate it to destinations like data warehouses for use with business intelligence (BI) tools.How do you make an ETL?
Create a New ETL Process- Select (Admin) > Folder > Management.
- Click the ETLs tab.
- Above the Custom ETL Definitions grid, click (Insert new row).
- Click Save.
- Click the ETL Workspace tab.
- Notice this new ETL is now listed in the Data Transforms web part.
How do you make a pipeline in Python?
In this tutorial, we're going to walk through building a data pipeline using Python and SQL.The script will need to:
- Open the log files and read from them line by line.
- Parse each line into fields.
- Write each line and the parsed fields to a database.
- Ensure that duplicate lines aren't written to the database.


